Last updated: 17 May 2026
Help Documentation
Automations
Automations enable you to design and configure the sequence of Actions to be executed automatically, based on triggers or conditions. These automated workflows, or Automation Flows, consist of individual steps called Operators, which can perform a wide range of tasks such as processing emails, running Activities, interacting with LLM models, or exchanging data with webhooks. By combining and chaining these Operators together, you can create customized Automations to streamline processes, optimize workflows, and enhance overall efficiency.
Navigating to the Automations Page
- Click on the Toolbox icon on the left-hand Menu Bar to get to the Toolbox.
- Click on the Automations tool inside the Toolbox.
Configuring Automations
- Add a new Automation or select an existing Automation from the table.
- To add a new Automation, click the Add button in the top-left of the Automations window.
- Fill in the Automation Details:
- Name: Enter a name to identify your Automation.
- Automation Is Active?: Check this box to activate the Automation and allow it to be triggered. The Trigger Operator will control how the Automation is initialized.
- Description (Optional): Provide a text description of this Automation to help users quickly understand its function.
- Save the configuration:
- Click the Save button in the bottom-right corner of the Automation Details window. Note that when creating a new Automation, the details page must be saved before you can access the Flow tab and History tab.
Flow Tab
The Flow tab is where the Automation Flow for the Automation is set up. This controls the logic for the Automation, which will perform its actions in order from top to bottom. There are four kinds of Operators: Triggers, Actions, Conditionals, and Operations operators. Each Automation Flow will start with one Trigger Operator followed by a series of Action Operators.
Using the Flow Tab
- In the Flow tab, a list of Operators is available on the left side of the screen. You can hide or show this list by clicking the double arrow tab near the top of the Operators panel.
- To use an Operator, drag it from the Operators panel onto the Automation Flow view screen. Once placed, the properties panel for this Operator will open on the right side of the window, allowing you to configure its settings.
- The buttons to the right of the Operators panel can be used to control the view of the Automation Flow. Use the "+" and "-" buttons to zoom in and out, and the box button to reset the view to the closest zoom possible.
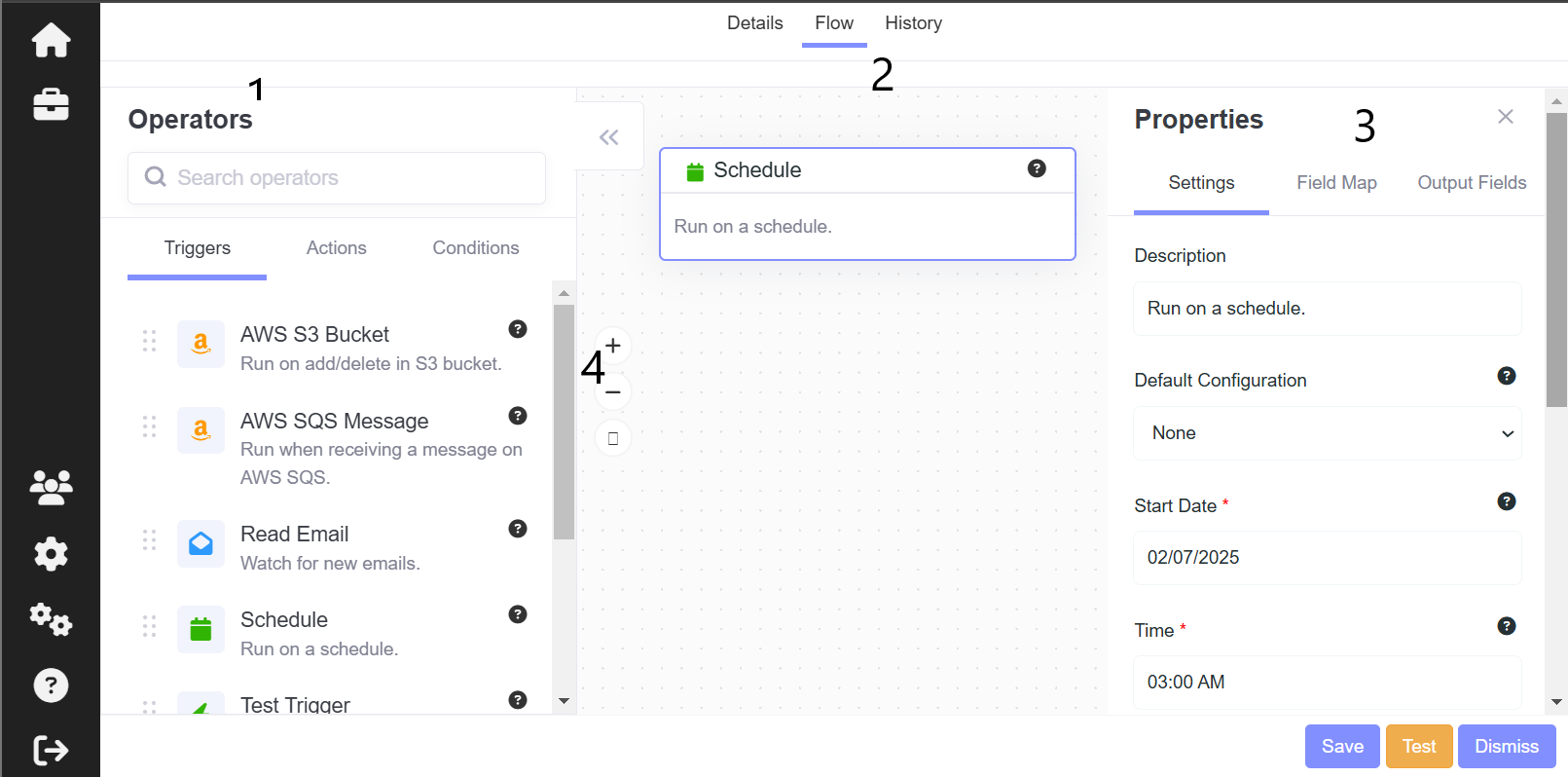
Using the Flow Tab (Shown above)
- Operator List A list of Operators is available on the left side of the screen. To hide or show this list, click the double arrow tab near the top-left of the Operators window.
- Automation Flow: Drag an Operator from the Operators panel onto the Automation Flow panel in the center of the window. Once placed, the properties panel for this Operator will open on the right side of the window.
- Operator Properties: This panel shows the details of the currently selected Operator. It includes the Settings, Field Map, and Output Fields tabs.
- View Controls: The buttons to the right of the Operators panel can be used to control the view window for the Automation Flow.
- The "+" and "-" buttons cause the Flow to zoom in and out.
- The box button will reset the view to the closest zoom possible.
For more details about the Flow tab, please see Working With The Automation Flow.
Editing an Existing Workflow
- Replacing a Trigger: To replace an existing Trigger, click on the new Trigger from the Operators panel on the left side of the screen. A popup will appear asking you to confirm the replacement. If there are any Field Mappings related to the existing Trigger, they will need to be removed from children prior to replacement.
- Deleting an Action or Conditional Operator: When deleting an Action on Conditional Operator, there is the option to remove it along with its child operators or leave them intact and move them up.
The Remove button and Delete icon will both function the same as above.
To delete an Action or Condition:
Click the red delete icon located in the top-right corner of the Operator block, or Click Remote button within Properties, then:
- To delete the child operators along with the Action, check the "Delete Child Operators" checkbox. Click Save.
- To just delete the Action and move the child operators a step up, click Save.
- Moving an Operator from one parent to another: Click and drag the operator from its current parent and drop it below the target operator where you want to place it. This operator will be moved along with its child operators. Validation will be performed at Apply or Save for all the Operators that were moved.
- Enabling or Disabling Action Operators: Action and Conditional operators (and their children/branch) can be disabled without affecting the rest of the automation. When disabled, the entire branch underneath will be disabled. The automation will run without those disabled operators running. This prevents having to delete the operator and its children. To add the operator (and its children/branch) back to the flow, simply re-enable it.
Copying Operator Within a Flow
An Operator (Action or Conditional) can be copied to reuse it within a flow. The Operator will be copied together along with it child operators and field values.
To copy an Operator:
- Click on the Operator you want to copy.
- Hold the Alt key on Windows or the Options key on IOS and drag the Operator under the target operator.
Important: If any mappings are disconnected due to the reorganization, those mapped fields are cleared and will show as warnings.
Validation Warnings
If a user adds or deletes an operator in an Automation Flow or does an Apply or Save, the Automation Flow validates the mappings. If the mappings are invalid, the operator(s) in the flow with the conflicts gets highlighted. The automation can still be saved, however, the automation cannot be activated until the conflicts are resolved.
The indicator is displayed on the Apply button if any operator has pending changes to apply, and on the Save button if there are any unsaved changes, including those in the Details
History Tab
The History tab shows instances where the current Automation was triggered or tested.
- To see more details about an entry, click the green "+" button on the left side of the table. This will show a breakdown of each Operator that ran and the status of the Automation at that time.
- While the Automation is processing, the status of completed and currently running Operators will show.
- Within the details of an entry, you can click the double arrow next to each Operator to show additional details about that Operator.
- Note: Any Operator that returns HTML in the response will have a toggle to swich between Raw and Rendered HTML.
- Press the Refresh button in the top-left of the window to retrieve any recent instances of the Automation being triggered or tested.
- For long running Automations, the latest run will start as Queued. Once the Automation is in progress, the status will change to In Process. Once complete, the Status will show the final result of the Automation.
Important: Our servers use GMT time for any scheduling-related actions to maintain standardization between servers, users, and our team. Time will be displayed in the Timezone set within Account Settings.
Filter and Advanced Filters
Filter: In the History Tab, the filter function helps to narrow down the displayed data by allowing users to enter a specific keyword. By applying a filter, only the relevant data points will be shown in the history tab for easier analysis. It allows us to filter using the Status as well.
Advanced Filters: Advanced Filter allows filtering based on the Date parameter, enhancing the ability to extract required data from the history tab. It includes 'Start Date' and 'End Date' fields, allowing users to extract data within the selected date range.
Working With The Automation Flow Tab
The Automation Flow Tab is a powerful and flexible tool used for creating customized and efficient automation flows. Each operator provided in the Flow Tab has unique properties and potential configurations, allowing for endless possibilities in automating tasks and processes.
To make the most of the Flow Tab, start by outlining your automation goals and breaking down complex workflows into manageable steps. This simplifies the configuration process and allows you to create Automations tailored to your specific needs.
Tips for Working With the Automation Flow Tab
- Start simple: Begin with a basic Automation Flow to familiarize yourself with the interface and Operator functionalities. You can gradually add more complexity as you become more comfortable with Automations.
- Use descriptions: Utilize the description fields for Operators and Automations to describe their purpose and functionality. This can be helpful for future reference and for other team members who may work on the Automation.
- Test frequently: Regularly test your Automation at different stages of development. This helps identify any issues early and ensures each part of the Automation is working as expected.
- Reference the documentation: Refer to the detailed documentation for each Operator to understand the specific configurations and use cases.
- Be mindful of the Field Map tab: The Field Map tab allows you to dynamically link properties between Operators. This can create powerful Automation Flows, but requires careful planning to ensure the data flows correctly between steps.
- Utilize the Output Fields tab: Check the Output Fields tab to understand what data each Operator can provide to downstream Operators.
Operator Properties
When you select an Operator within your Automation Flow, a Properties panel will open on the right side of the window. This panel is used to control the settings of the selected Operator. Below is a quick overview of the three tabs within the Operator Properties panel.
Settings Tab
The Settings tab is the main tab for controlling the inputs for your Operator’s properties. All of the properties are shown with any applicable fields or dropdown menus for entering values. Any values entered here are considered "static values" and will remain constant throughout the Operator's execution. There is also a picklist field called 'Default Configuration' that enables you to choose a default configuration (trigger or action). This will automatically populate all fields for that operator with default configuration values wherever available. The fields that are automatically populated from the Default Configuration will be highlighted in green .
For security reasons, values set in Default Configurations within an Operator are not able to be passed to the next Operator, as these may be secured values. Therefore, any fields that are mapped to a parent Operator that has a default configuration will cause the automation to fail.Note: When a Default Configuration is Deactivated or Deleted, the configuration values will be removed from the fields and the Automation will be set to inactive.
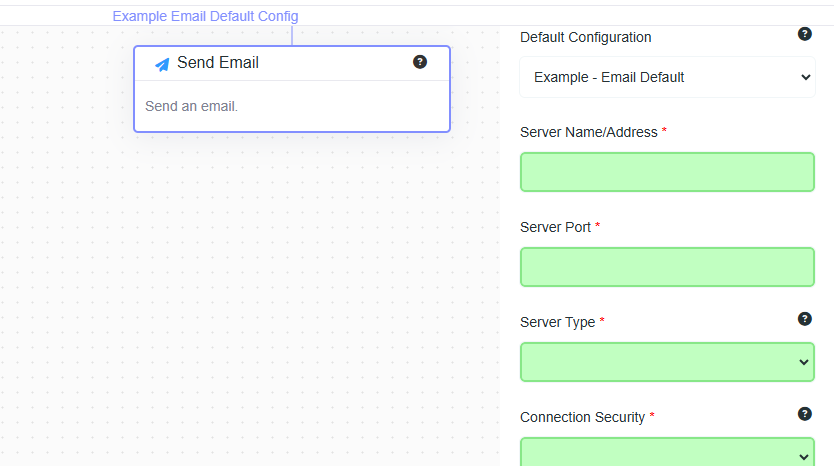
- The Following Operators are currently not available to set up a Default Configuration:
- Triggers
- Test Trigger
- Actions
- Add/Map Fields
- Aggregator
- Base64
- Best Match
- Fuzzy Matcher
- JSON Parser
- MD5 Hash
- Transcription History
Field Map Tab
Within the Field Map tab, you can set a property from the Settings tab to use any generated output from an Operator higher up in the Automation Flow. When a property is set here, it becomes “locked” on the Settings Tab, indicating that the field has been “mapped.” Description of the operator is in the dropdown along with the operator.
Clearing Field Maps: To clear a selected value from a Field Map, click the blank entry that appears as the first selection in the dropdown options.
Output Fields Tab
This tab shows the available output fields that the selected Operator will provide, along with the names of those fields. This can be used for quick reference when setting up field mappings and to double-check that an Operator has the correct outputs you are expecting.
Operator Details
Trigger Operators
Trigger Operators are essential components in Automation Flows, as they initiate the flow based on various actions or sources. These sources may include predetermined schedules, webhooks, or emails. It's important to note that only a single Trigger Operator can be incorporated into an Automation Flow. Unlike other operators, Triggers do not require field mappings due to their position at the beginning of the flow.
The currently available Trigger Operators include:
- AWS S3 Bucket - Activate when an object is added or deleted from an S3 Bucket.
- AWS SQS Message: Activate whenever a new message is added to a SQS queue.
- Lula Chat Completed: Activate whenever a LuLa bot chat session ends.
- OpenAI API - Allows OpenAI compatible API to trigger automations.
- Read Email - Activate when an email arrives at the specified address.
- Read Email (Office 365) - Activate when an email arrives at the specified Office 365 inbox.
- Schedule - Activate at a specific time, date, or weekly schedule. The time provided will be run based on the GMT timezone, but will be displayed in the Timezone set within Account Settings.
- Symbient Automation Trigger - Allows triggering a Symbient Automation with a Trigger Symbient Automation Action operator.
- Test Trigger - Activate whenever creating and testing automations from the UI.
- Transcription - Access a saved Transcription.
- Webhook: Allows to set up an automated response when a specific event occurs
Important: Our servers use GMT time for any scheduling-related actions to maintain standardization between servers, users, and our team. Time will be displayed in the Timezone set within Account Settings.
To read more about the Trigger Operators, Click Here .
Action Operators
Action Operators are used to continue the Automation Flow after the Trigger Operator is activated. Actions include a wide variety of functions such as running an Activity, scraping a website, transcribing audio, or sending an email.
The available Action Operators are:
- Activity - Perform a predefined Activity from the list of currently active Activities.
- Add/Map Fields - Create one or more Output Fields populated with data that can be used by other Operators.
- Aggregator - Combine data from multiple Operators into a single JSON object that can be passed to other Operators.
- AWS Lambda - Invokes pre-configured functions within the AWS ecosystem.
- AWS S3 DELETE - Delete an object from an AWS S3 bucket.
- AWS S3 GET - Get an object from an AWS S3 bucket.
- AWS S3 PUT - Update an object within an AWS S3 bucket.
- AWS SQS Send - Used to send messages to an Amazon SQS queue.
- Base64 - Encodes or Decodes the Input string to/from Base64 depending on the Action selected.
- Best Match - Used to identify a close match for a given input or when an exact match is not available.
- Call Webhook - Send a JSON object to a webhook endpoint.
- Classify - Run a Classification Model on the given text.
- Concatenate Strings - Allows automation to combine multiple strings into a single, unified string.
- Context Search - Searches a large body of text for one or more specified words or phrases.
- Convert Data - Converts data from one format to another.
- Document Extractor - Locate and extract information from Word Docs and PDFs.
- Fuzzy Matcher - Perform a fuzzy match comparison between two inputs.
- Google Docs Create - Creates a Google doc.
- Google Docs Read - Reads from a Google doc.
- Google Docs Write - Writes to a Google doc.
- Google Sheets Create - Creates a Google sheet.
- Google Sheets Read - Reads from a Google sheet.
- Google Sheets Write - Writes to a Google sheet.
- HTTP GET - Submit a GET request to the specified address.
- HTTP POST - Submit a POST request with a payload to the specified address.
- HTTP PUT - Submit a PUT request with a payload to the specified address.
- JSON Parser - Parse JSON data to be used for other Operators.
- LLM - Send text to an LLM Model for inference.
- MD5 Hash - This is useful for hashing credentials or other information before sending it to external systems.
- Run JS Code - Used to run a custom JavaScript code.
- Save Draft - Save an email draft.
- Save Draft (Office 365) - Save an email draft using an Office 365.
- Save LLM Datasource - Creates or updates an LLM Datasource.
- Scrape Website - Scrape a website for text data.
- Search Web - Performs a web search from the query.
- Send Email - Send an email using an email SMTP server.
- Send Email (Office 365) - Send an email using an Office 365 email server.
- Transcribe Audio - Send an audio file to be transcribed by Symbient ASR.
- Transcription History - Append an output to the Activity tab of a Transcription.
- Transcription Lookup - Access a Transcription that has already been processed.
- Transcription Update - Save a Transcription and update the text.
- Trigger Symbient Automation - Trigger another Automation that has a Symbient Automation Trigger.
- Uptime Monitor - Send Request to an Uptime Monitor that has Monitor Type set to “API”.
To read more about the Action Operators, Click Here .
Conditional Operators
Conditional Operators are "gates" that allow or prevent the logic flow to continue through the current branch. If a conditional returns 'true' for a path, the logic for that branch continues. If the conditional is 'false', then the logic for that branch is stopped.
Data Types Evaluated by Conditional Operators
Conditional Operators compare the following based on predefined logical and mathematical criteria:
To read more about the Conditional Operators, Click Here .
Operation Operators
Operation Operators are used to allow Automations to loop over list items and perform actions on each element individually.
The available Operation Operators are:
- Add To List - Adds items to the list.
- Iterate Operator - Iterates the list.
- Make A List - Creates a list.
- Merge - Merge branches back together.
- Remove From List - Removes items from the list.
To read more about the Operation Operators, Click Here .
Glossary of Terms
Actions
Action Operators are the components used to continue the Automation Flow after a Trigger Operator has been activated. They perform a wide variety of tasks such as running an Activity, scraping a website, transcribing audio, or sending an email. Actions enable the execution of specific tasks within an automation, guiding the flow toward achieving its objectives.
Activity
Activities are predefined sets of instructions or actions that can be executed within various areas of Symbient AI. An Activity is typically associated with an LLM Model and involves tasks like summarizing a transcript, extracting specific information from text, or performing other natural language processing tasks. Activities are integral to automating complex tasks that require language comprehension and processing.
Automation
Automations are in-depth logic systems that perform a series of tasks automatically. These systems are built using individual steps called Operators, which can handle functions like reading or sending emails, running an Activity, passing text to an LLM Model, or writing data to a webhook. By chaining these Operators together, you create an “Automation Flow,” allowing complex processes to be executed seamlessly.
Automation Flow
An Automation Flow is the sequence of steps or operations that an Automation follows. It is designed and set up in the Flow tab of Symbient AI, where the logic of the Automation is defined. The flow dictates the order in which actions are performed, starting from the Trigger Operator and moving through a series of Action Operators.
Field Mapping
Field Mapping is the process of connecting Operator fields to output fields from Operators that are earlier in the Automation Flow. For example, you might retrieve the text from a transcription using the Transcription Lookup operator and then map that data to the Input field of an LLM operator. This allows data to flow seamlessly between different steps in the Automation, ensuring that each Operator has the necessary information to perform its function.
Instruction
Instructions are used to give detailed step-by-step directions for the AI to follow in order to complete a specific task, typically in a more structured manner. They are often used when the AI needs to perform a complex or multi-step operation.
Instructions are more structured and tend to follow a specific format that outlines the necessary steps for the AI to complete a task. They are often written in a more direct tone, using words like "do," "perform," or "execute" to guide the AI.
Operator
Operators are the building blocks of an Automation. They are the individual steps within an Automation Flow, each designed to perform a specific function or task. Operators can either trigger actions, process data, or interact with external systems, making them essential for creating effective and dynamic Automations.
Prompt
Prompts are generally used to provide context, request information, or initiate a conversation with an AI. They usually seek a response or action from the AI to help guide the conversation or task.
Prompts are often open-ended, allowing for flexibility in the response or action provided by the AI. They can be as simple as a question or as complex as a detailed scenario.
Trigger
Triggers are Operators that initiate the start of an Automation Flow. They are activated based on specific conditions or events, such as receiving an email, a scheduled time, or a webhook call. Triggers are essential for starting the sequence of actions that make up an Automation.